HiFi-GAN: High-Fidelity Denoising and Dereverberation Based on Speech Deep Features in Adversarial Networks
Interspeech, to appear, October 2020
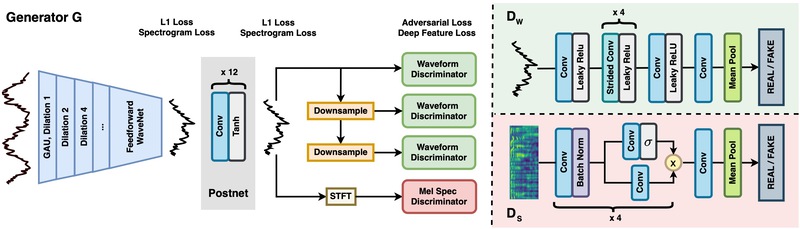
GAN Architecture. Generator G includes both a feed-forward WaveNet for speech enhancement, followed by a convolutional Postnet for cleanup. Discriminators evaluate the resulting waveform (D_w, at multiple resolutions) and mel-spectrogram (D_s).
Abstract
Real-world audio recordings are often degraded by factors such as noise, reverberation, and equalization distortion. This paper introduces HiFi-GAN, a deep learning method to transform recorded speech to sound as though it had been recorded in a studio. We use an end-to-end feed-forward WaveNet architecture, trained with multi-scale adversarial discriminators in both the time domain and the time-frequency domain. It relies on the deep feature matching losses of the discriminators to improve the perceptual quality of enhanced speech. The proposed model generalizes well to new speakers, new speech content, and new environments. It significantly outperforms state-of-the-art baseline methods in both objective and subjective experiments.
Links
- Paper
- Project Page (examples, code, and data)
Citation
Jiaqi Su, Zeyu Jin, and Adam Finkelstein.
"HiFi-GAN: High-Fidelity Denoising and Dereverberation Based on Speech Deep Features in Adversarial Networks."
Interspeech, to appear, October 2020.
BibTeX
@inproceedings{Su:2020:HiFi,
author = "Jiaqi Su and Zeyu Jin and Adam Finkelstein",
title = "{HiFi}-{GAN}: High-Fidelity Denoising and Dereverberation Based on
Speech Deep Features in Adversarial Networks",
booktitle = "Interspeech, to appear",
year = "2020",
month = oct
}